The adoption of Generative AI (GenAI) is rapidly gaining traction, creating new opportunities for more advanced and complex use cases. At ContractPodAi, we are witnessing these changes in real-time—the evolution of use cases that require advancements in AI models from general use cases to domain-specific and customer-specific cases.
Transition from Single to Multi-Model Strategy
 Most initial applications for Generative AI were targeted at simpler task-oriented use cases where a single Large Language Model (LLM) was sufficient to achieve the desired outcome, but that is quickly changing. At ContractPodAi, we built our GenAI solutions with a multiple Large Language model strategy. One lesson from our experience is that AI models are not “one size fits all” solutions. Certain LLMs are better at specific tasks than others—for example, some excel at generating content, while others are ideal for concluding advanced analysis. As customers onboard GenAI solutions, they realize that a one-size-fits-all LLM strategy falls short at the enterprise level. Relying on one model can lead to limitations, especially for specialized tasks and advanced use cases.
Most initial applications for Generative AI were targeted at simpler task-oriented use cases where a single Large Language Model (LLM) was sufficient to achieve the desired outcome, but that is quickly changing. At ContractPodAi, we built our GenAI solutions with a multiple Large Language model strategy. One lesson from our experience is that AI models are not “one size fits all” solutions. Certain LLMs are better at specific tasks than others—for example, some excel at generating content, while others are ideal for concluding advanced analysis. As customers onboard GenAI solutions, they realize that a one-size-fits-all LLM strategy falls short at the enterprise level. Relying on one model can lead to limitations, especially for specialized tasks and advanced use cases.
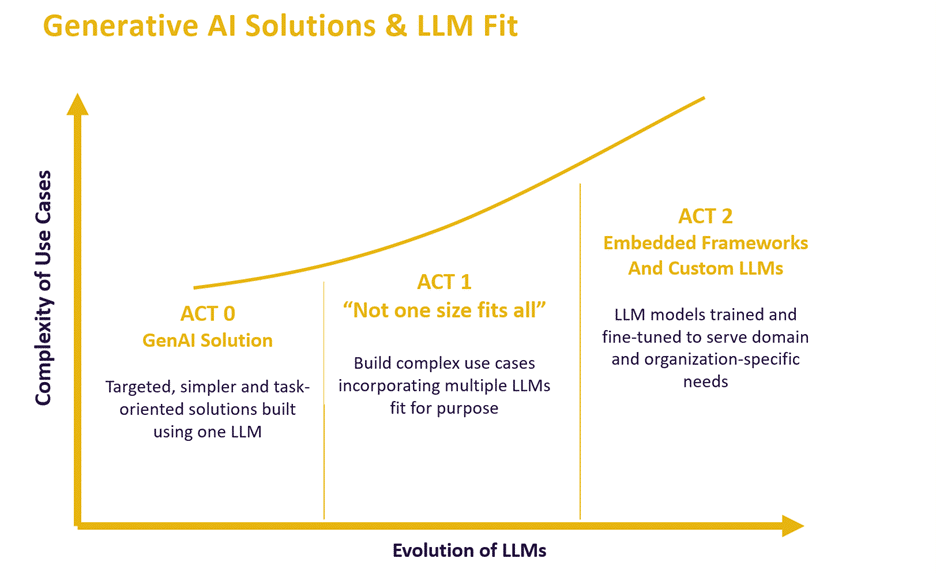
A more sophisticated LLM strategy is required as use cases grow and become more complex. Accuracy and scalability are essential for more complicated use cases like analyzing legal documents with sensitive information. This requires a mix of best-of-breed LLMs. Suppose you are driving an obligation report and analysis across a repository of contracts. In that case, the solution needs to be able to analyze the interlinked documents, extract key information, understand the context of the documents, drive sequential and complex analysis, and then generate output in the desired format. In this example, the solution needs to handle and perform multiple tasks precisely. Accomplishing this level of analysis and output requires utilizing capabilities from several different LLMs.
The Need for Embedded Frameworks and Custom Models
General purpose models could perform very well on many tasks. Still, these models require fine-tuning with high-quality, domain-specific data for specialized fields like the legal sector. Taking it a step further, as companies start adopting AI, they’ll need to further fine-tune models to align with their legal and compliance knowledge base. Examples include legal analysis, reviewing and redlining, or drafting legal documents. Organizations will have their own internal use case for legal analysis based on their industry, regulations, etc. a one-size-fits-all model does not scale or account for domain nuances.
Leah: Gold Standard Embedded and Custom Legal Models
Leah is model agnostic—a task or use case could require services from multiple models. Additionally, Leah has an embedded framework, and models fine-tuned for legal available to our customers as the gold standard. Customers can further fine-tune the models via an easy-to-use intelligent interface. This innovative capability is the first to market in the legal sector, making it possible for customers to fine-tune the model to their specific requirements.
Take redlining as an example; Leah Contract Review has an embedded framework and fine-tuned models as the gold standard for redlining. As needed, customers can easily fine-tune the model to specific redline rules applicable or required for their legal operations. Similarly, Leah’s models can be fine-tuned to perform complex legal analysis or set the standard for drafting legal documents.
Training Methodologies
 We use various techniques for fine-tuning the models, including fine-tuning the model behavior through Retrieval Augmented Generation (RAG) and building fine-tuned legal domain LLMs with high-quality data.
We use various techniques for fine-tuning the models, including fine-tuning the model behavior through Retrieval Augmented Generation (RAG) and building fine-tuned legal domain LLMs with high-quality data.
Leah offers embedded gold standard models for the legal domain. Customers can use these models in combination with the ContractPodAi Knowledgebase from day one. Leah also enables customers to create embedded custom models for their specific use cases using Retrieval Augmented Generation (RAG). The model behavior can also be fine-tuned for legal and customer-specific domains through context ingestion, customer-specific frameworks, and prompt engineering.
Additionally, for some complex legal use cases, the baseline models need to be further trained with high-quality data to perform at the desired precision. For further training the baseline LLMs, we use methods such as response scoring with Reinforcement Learning through Human Feedback (RLHF) and reinforcement learning through AI Feedback (RLAIF). In this process, having use cases specific and high-quality data is the primary driver of success in producing high-quality and reliable models.







